Surpassing Frontier Performance with Fusion
Brian Thomas ·

On this page
- Panels of Models Consistently Outperform on Deep Research
- One API call that fuses the best output of multiple models
- We chose DRACO to test reasoning, tool calling, and succinctness
- Preventing the Models from Cheating
- Significant boost from fusing a model with itself
- Notes on our DRACO implementation
- Give Fusion a try
- 6/14 Update: FAQ from the Launch
We’ve found that synthesizing the results of multiple models can significantly outperform what individual models are capable of. Introducing Fusion: a tool for getting these combined results just as easily as calling a single model. It allows you to choose a panel of participant models alongside a judge model responsible for fusing the individual results together.
To understand the benefits of Fusion, we used a deep research benchmark that tests the combination of reasoning, tool usage, and knowledge. We found that:
- Panels consistently outperform individual models
- Beyond-frontier performance can be achieved with frontier panels
- Panels of budget models can surpass frontier models and get close to frontier panel performance
Try Fusion now in a chatroom, or check out the API docs to build it into your application.
Panels of Models Consistently Outperform on Deep Research
We tested Fusion on 100 deep research tasks from the DRACO benchmark. Some highlights of what we found:
- Fable 5 + GPT-5.5 fused together scored 69.0%**, surpassing every individual model, including Fable 5 alone at 65.3%**.
- A budget panel (Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro) beat GPT-5.5 and Opus 4.8. It came within 1% of Fable 5’s score while being 50% of the cost.
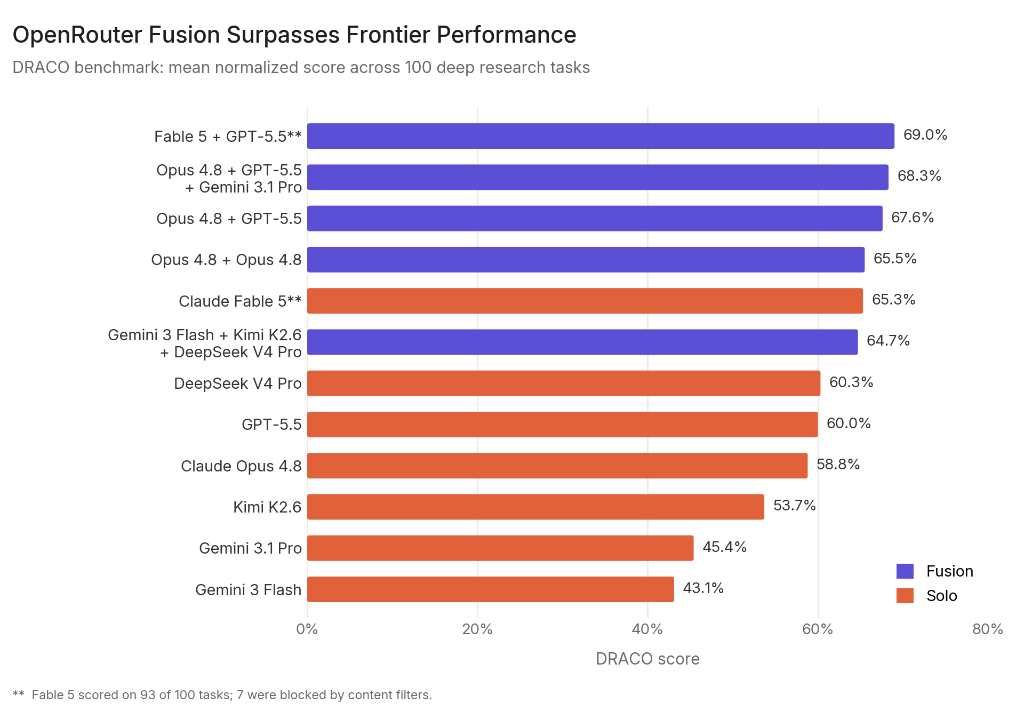
| Type | Model(s) | Score |
|---|---|---|
| Fusion | Fable 5 + GPT-5.5** synthesized by Opus 4.8 | 69.0% |
| Fusion | Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro synthesized by Opus 4.8 | 68.3% |
| Fusion | Opus 4.8 + GPT-5.5 synthesized by Opus 4.8 | 67.6% |
| Fusion | Opus 4.8 + Opus 4.8 synthesized by Opus 4.8 | 65.5% |
| Solo | Claude Fable 5** | 65.3% |
| Fusion | Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro synthesized by Opus 4.8 | 64.7% |
| Solo | DeepSeek V4 Pro | 60.3% |
| Solo | GPT-5.5 | 60.0% |
| Solo | Claude Opus 4.8 | 58.8% |
| Solo | Kimi K2.6 | 53.7% |
| Solo | Gemini 3.1 Pro | 45.4% |
| Solo | Gemini 3 Flash | 43.1% |
** 7 of the 100 DRACO tasks were not completed because Fable 5’s content filters blocked them from executing. We chose not to fall back to Opus 4.8 for those tasks, so the Fable results reflect 93 scored tasks rather than the full 100. This gives the most accurate picture of Fable’s own performance, but means direct score comparisons against models that completed all 100 tasks are slightly uneven.
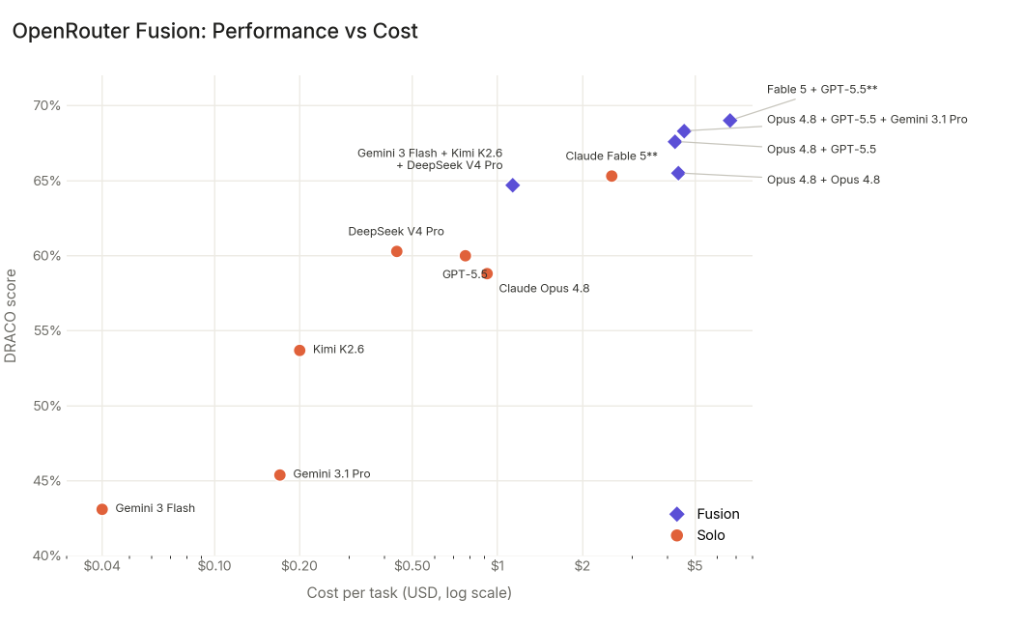
We believe this demonstrates the benefits of model diversity, similar to the benefits seen on human team performance. Bringing multiple different perspectives to complex problems yields superior results.
One API call that fuses the best output of multiple models
When you send a prompt to Fusion, we dispatch it to a panel of models in parallel, each with web search and web fetch enabled. A judge model reads every panel response and produces structured analysis: consensus points, contradictions, partial coverage, unique insights, blind spots. The calling model then writes the final answer grounded in that analysis.
The whole pipeline runs server-side so it can be called just like you would an individual model.
Call Fusion directly with a single model slug:
{
"model": "openrouter/fusion",
"messages": [
{ "role": "user", "content": "What are the strongest arguments for and against carbon taxes?" }
]
}Or customize the panel:
{
"model": "openrouter/fusion",
"messages": [{ "role": "user", "content": "..." }],
"plugins": [{
"id": "fusion",
"model": "google/gemini-3-flash-preview",
"analysis_models": [
"google/gemini-3-flash-preview",
"moonshotai/kimi-k2.6",
"deepseek/deepseek-v4-pro"
]
}]
}We chose DRACO to test reasoning, tool calling, and succinctness
We needed a benchmark that could tell the difference between a model that sounds thorough and one that actually is. Standard benchmarks test factual recall or reasoning puzzles. They don’t test the thing Fusion is built for: researching a complex question, synthesizing multiple sources, and producing a comprehensive, well-cited analysis.
DRACO (by Perplexity AI) is designed for this. It contains 100 deep research tasks spanning 10 domains: academic research, finance, law, medicine, technology, UX design, general knowledge, needle-in-a-haystack retrieval, personalized assistance, and product comparison.
Each task comes with a rubric of roughly 39 weighted criteria across four categories:
- Factual Accuracy (~20 criteria): verifiable claims the response must get right
- Breadth & Depth (~9 criteria): synthesis quality, trade-off analysis, actionable guidance
- Presentation Quality (~6 criteria): terminology, formatting, readability
- Citation Quality (~5 criteria): primary source citations with working references
Criteria can carry negative weights. Meeting a negative criterion means the response contains an error. For example, dangerous medical advice carries a big penalty. These negative criteria also make it hard to game the score by being verbose: a model that confidently states wrong things gets punished.
Each response is graded per-criterion by a judge model, three independent times. We reported the mean normalized score (0-100) across all tasks.
DRACO has limitations the authors acknowledge: it evaluates text-only, English-only interactions, and its static task set may not fully generalize to future deep research applications. Absolute scores also depend on judge model choice (the paper reports 10–25 point shifts between judges), though relative system rankings remain stable.
Preventing the Models from Cheating
When we gave the panel models web search, we discovered something alarming: they were finding the DRACO grading rubric online. While this was coincidental from search terms rather than intentional cheating, it still exposed a real contamination risk.
We solved this by excluding the locations where the results are hosted from web search and web fetch, preventing models from accessing pages related to the benchmark rubric. OpenRouter’s server tools support these exclude lists universally across all models by using a third party provider like Exa or Parallel, so applying them was a one-line config change rather than per-model patching. All results in this post were produced after the exclusion lists were in place.
If you are running your own evals, the same mechanism is available: pass excluded_domains to web_search or blocked_domains to web_fetch in your tool definitions to prevent the panel from accessing specific sources.
Significant boost from fusing a model with itself
We ran Opus 4.8 partnered with itself as a two-model panel, with Opus 4.8 also serving as the synthesizer. The result: 65.5%, a 6.7-point jump over solo Opus 4.8 (58.8%). This suggests that a meaningful chunk of Fusion’s lift comes from the synthesis step itself, not just from combining different model architectures. Running the same prompt twice produces different reasoning paths, different tool calls, different source selections. It’s not enough to outperform a diverse set of models, but helps us understand the impact of the synthesis itself.
Notes on our DRACO implementation
We carefully replicated the methodology described in the DRACO paper with the exception of using Gemini 3.1 Pro Preview as judge instead of the paper’s choice of Gemini 3 Pro. This means our scores are not directly comparable to the original paper’s published results.
We wanted to preserve the high human–LLM alignment properties that led to the authors’ selection, while capturing the discernment of the newer model. We sanity-checked our judging with Claude Sonnet 4.6 after Gemini 3.1 Pro Preview scored low on the benchmark itself, finding that it preserved the qualities that led to the authors’ selection as judge. Our goal was to show relative differences between Fusion and individual models.
Give Fusion a try
API: Send "model": "openrouter/fusion" to directly call Fusion, or add {"type": "openrouter:fusion"} to your tools array to let the model decide when to use it. Fusion docs
Chatroom: Open openrouter.ai/fusion and pick a preset or build a custom panel.
6/14 Update: FAQ from the Launch
The response to Fusion has been incredible. Thank you! We are reviewing all of the feedback, suggestions, and bug reports. Several improvements have already been shipped and we’ll continue to address over the next couple days. Here are answers to some of the most common questions we’ve been asked:
Is Fusion a drop-in replacement for Fable?
No. The benchmark shows that fusing multiple models together can reach and surpass Fable-level performance on deep research tasks. We benchmarked one class of tasks (DRACO deep research), but the approach likely extends to many other workflows we haven’t tested yet. We’d love to hear about other use cases where you find it works well.
DRACO also doesn’t include long-horizon tasks, which is where Fable shines.
How should I use Fusion for coding?
Fusion isn’t a drop-in replacement for coding models. Instead, it gives your coding model access to a server tool. The base model handles routine coding directly and can choose to call Fusion selectively on questions worth spending more time and money to get a thorough answer (e.g. architecture decisions or research on best practice approaches). The model decides when the question warrants multiple perspectives.
What tools did the benchmark models have access to?
Every model, both in Fusion panels and solo runs, had the same three server tools:
Keeping the tool set identical across all configurations ensured a fair comparison. The Fusion panels and solo runs differed only in whether multiple models’ outputs were synthesized, not in what tools were available.
DeepSeek V4 Pro’s performance was surprising. Is that accurate?
We were surprised by how well DeepSeek scored. At 60.3%, it performed similarly to both Opus 4.8 and GPT-5.5.
One hypothesis: Opus 4.8 would score higher with a larger tool-calling budget. It seems to be a hungrier model that performs better with more time and more tool use. Fable, by contrast, was better at using the tool-call budget judiciously and thinking for longer before acting. The benchmark’s fixed tool-call budget may have compressed the gap between models with different tool-use strategies.
Is it slow? How much slower?
The model you make a request to performs the same as it would normally. The responses are only slower when your model encounters a problem that it thinks will benefit from using Fusion. When Fusion is invoked, it kicks off a multi-step process that is often 2-3x longer than a standard call. During this time it sends your prompt to multiple models, waits for them all to finish, then processes the results to produce the fused response. We did it this way to balance the speed of normal model execution with the availability of beyond-frontier answers to questions when you need it.
What are all the ways I can use Fusion?
There are four ways to use Fusion and they all use the same underlying logic:
- Chatroom. Open openrouter.ai/fusion and pick a preset or build a custom panel. No code needed.
- Model slug. Send
"model": "openrouter/fusion"to any of our inference endpoints and the Fusion plugin is auto-injected with a default panel of frontier models. You can simply swap your model string to use it. Docs - Server tool. Add
{ "type": "openrouter:fusion" }to your tools array. Most control: pick the model you want to do the fusion, and combine Fusion with other tools. The model you send the request to will decide when and if it invokes Fusion. Docs - Plugin. Make a call to completions or responses like you would normally then add
"plugins": [{ "id": "fusion", ... }]with your selected panel. The model you specify in the call will be the one that fuses the results. Docs